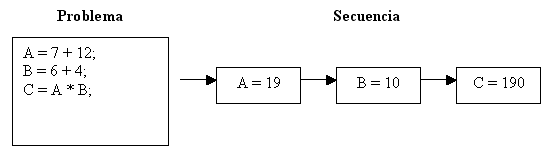
El proceso de resolver una determinada tarea por parte de un computador, tal y como tradicionalmente se entiende, es un proceso secuencial. Disponemos de una lista de instrucciones y datos que el computador va ejecutando a medida que los lee. La figura siguiente muestra un ejemplo simplificado.
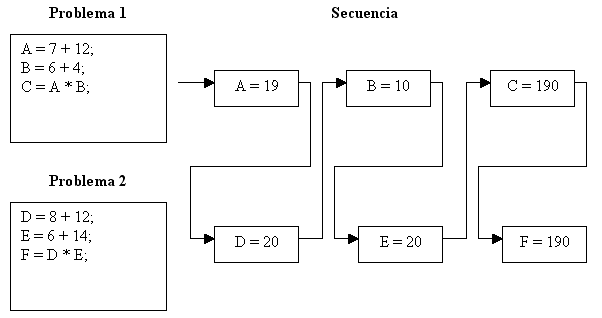
Los computadores pueden funcionar en multitarea, en el sentido de que pueden gestionar (ejecutar) varias tareas no relacionadas a la vez, pero puede ser una multitarea ficticia, puesto que si se dispone de un solo microprocesador las distintas tareas tienen que irse turnando entre sí. Aparentemente se han resuelto los dos problemas de manera simultánea pero el tiempo que se ha tardado ha sido la suma del tiempo de los dos problemas, como vemos representado en la figura siguiente.
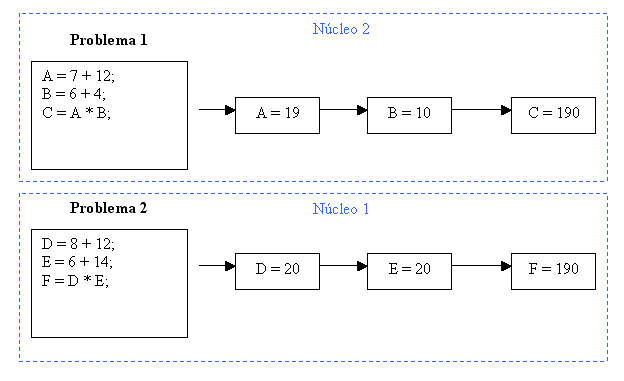
En los últimos años se han hecho populares los microprocesadores con múltiples núcleos (o cores), tales como los Intel Dual Core o la nueva familia Core Ix en los que disponemos no ya de uno sino de dos, cuatro o incluso ocho procesadores que comparten la memoria y son capaces de trabajar en paralelo. Su presencia se ha hecho normal en nuestros escritorios hoy en día. En un sistema con dos o más procesadores podemos efectuar una verdadera multitarea, ya que es posible ejecutar simultáneamente más de una instrucción, como mostramos en la figura siguiente.
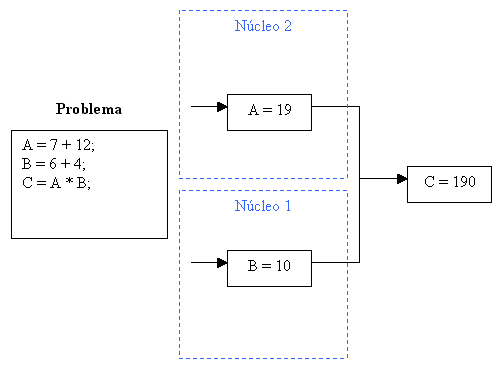
Surge entonces la idea de aprovechar esta capacidad para resolver problemas de una manera más rápida, empleando la computación en paralelo. En ella no queremos ejecutar varios problemas dispares de forma simultánea (como en el ejemplo anterior) sino que buscamos ejecutar un problema concreto lo más rápido posible. Esto se consigue mediante la paralelización, proceso por el cual pasamos de ejecutar un determinado programa secuencialmente a ejecutar varias partes del mismo a la vez, para dar el resultado final una vez se han calculado cada una de las partes (representado en la figura siguiente.
Hay que indicar que no todos los problemas son susceptibles de ejecutarse paralelamente sino que depende de su naturaleza (fundamentalmente que el resultado final dependa de resultados parciales no relacionados entre sí). Además, si un problema requiere un tiempo T para resolverse con un solo procesador, no significa que vaya a pasar a requerir T/2 con dos procesadores, T/3 con tres procesadores, etc. En la práctica, al ejecutar un programa en paralelo unas partes acaban antes que otras, o unas dependen de otras, y el proceso de sincronizar y comunicar los resultados parciales tiene un coste. Por ello llega un momento en que no se obtiene mejora aunque añadamos más procesadores.
A pesar de esos inconvenientes, los computadores dotados de múltiples procesadores trabajando en paralelo son la solución preferida a la hora de afrontar tareas que requieren gran cantidad de cálculo. Esto es así porque un único procesador no puede aumentar su velocidad ni memoria indefinidamente, mientras que nada nos impide (en teoría) unir tantos procesadores como queramos para que funcionen de forma simultánea formando un único supercomputador. Un buen ejemplo es el supercomputador Mare Nostrum de Barcelona, uno de los más potentes del mundo, que internamente está formado por 10.240 procesadores que funcionan en paralelo.
Generalizando este concepto nos encontramos con la llamada computación distribuida. En ella nuestro supercomputador es un computador virtual en el sentido de que no tiene existencia física como un ente concreto, sino que cada uno de sus procesadores (o nodos) es en sí mismo un computador independiente, estando todos ellos conectados entre sí a través de una red. Así, cada nodo recibe una tarea o problema, la lleva a cabo (resuelve), y devuelve el resultado (solución). Al final la suma del resultado de todas las tareas constituyen la solución al problema completo original.
Dentro de la computación distribuida identificamos la llamada computación GRID, que permite utilizar recursos de computación y almacenamiento dispersos de una forma homogénea y coherente. En estos sistemas cada uno de los procesadores es, no ya un computador independiente, sino que además los computadores son heterogéneos, con procesadores, memoria e incluso sistemas operativos distintos unos de otros, pero gracias a la implantación de una capa software denominada «middleware» podemos cohesionar (de alguna manera) y gestionar los recursos de cada equipo y su utilización conjunta.
Por último nos encontramos con la muy popular en los últimos años computación voluntaria (o Desktop Grid), en la que los computadores que forman la red de computación tienen la particularidad de ser anónimos, y se unen a ella de forma voluntaria y altruista.
Solving a specific task with a computer, as usually understood, is a sequential process where we dispose of a list of commands and data that the computer executes one after the other. The following figure shows a very simplified example.
Computers can work doing multitasking, meaning that they can deal with (execute) several non-related tasks at the same time. This multitasking may be fictitious as, with just one processor, tasks have to be executed in turns. Apparently the tasks have been solved at the same time, but the time required is the sum of the time required for all the tasks. This is shown in the following figure.
From some years ago, multiprocessors with several cores, such as Intel Dual Core or the Core Ix family, where not only one but two, four or even eight cores share memory and are able to work in parallel. Nowadays they are very common in our desktops. In a system with two or more processors we can carry on a true multitask, because we can execute simultaneously more than one command, as shown in the following figure.
Appears then the idea of using this ability to solve problems in a faster manner, using the parallel computing. With it we do not want to execute several unrelated tasks (as in the previous example) but to solve a specific problem as fast as possible. This is done by means of the so called parallelisation. With this, instead of executing a program sequentially we execute several parts at the same time, producing the final result once every part has been processed (shown in the following figure).
Note that not all problems may be solved with parallelisation but it depends on its own nature (mainly if the final result depends on partial results non related among them). In addition, if a problem requires a time T to be solved with a single processor, this does not mean that it will require T/2 with two processors, T/3 with three and so on. In real life, when executing a program in parallel some parts are completed before others, and the effort of synchronise and communicate the partial results has a cost in term of time. Because of this, there is a point where, no matter the processors you have, the time required is not improved.
Even with these drawbacks, computers with multiple processors are the preferred solution when facing tasks that require big amounts of calculations. This is because a single processor can not increase its speed and memory indefinitely, while nothing stops us from setting together (in theory) as many as we want to make them work simultaneously composing a single supercomputer. A good example is the Mare Nostrum supercomputer in Barcelona, one of the most powerfull computers in the world, composed of 10.240 processors.
Generalizing this concept, we define the so called distributed computation, where the supercomputer is a virtual computer meaning that it does not exist physically as an entity, and instead of it each one of its processors (or nodes) is itself an independent computer, being all them linked together using a network. In this way, each node receives a task or problem, solves it, and returns the result. At the end, the sum of the results form the solution to the original complete problem.